
This is everything you need to know to get a running start with PLCs if you’re already familiar with programming or engineering embedded systems.
Programmable Logic Controllers have been around a long time and there are tons of online resources devoted to the devices but I’ve found these lacking when it comes to addressing the concerns and mindset of people who already have solid foundations in programming other types of systems, like embedded/IoT or general purpose computers.
Here I’ll provide perspectives and lessons learned that will give you a quick leg up in the PLC world without having to slog through explanations of what a blasted variable actually is or the meaning of TRUE/FALSE.
PLC: a way of thinking
If you’re reading this you probably have a good clue of what a PLC is already, so I’ll only touch on a few points.
Now that even our tiny embedded chips can be programmed in C++ (or Python!) and sometimes even offer multi-core CPUs or threading, working with a PLC can feel like going back in time. They are programmed in weird languages, often with (very so-so) proprietary software, and have a bunch of limitations.
But these things are built for ruggedness and are hard real-time systems. Do it right, and your machine will chug along predictably (close enough to) forever.
For both historical reasons and to ensure the PLC meets the RT requirements, there are fancy things you might be used to that you just can’t do. And I’m being generous with ‘fancy’ here—for instance, simple recursion is one of the no-nos.
Though there are extensions and upcoming features, if you want to play safe you’ll stick to (perhaps even a subset of) the IEC 61131-3 standards, which started up in the 90s and were last updated about 6 years ago.
Among other things, the standard defines
- the core set of built-in datatypes (ubiquitous things like BOOL or UINT but also some interesting ones like TIME)
- the capacity to roll your own datatypes, using enumerations and structures which group built-ins and/or previously defined custom types
- a set of attributes you can assign to variables, to indicate where and how they are stored (e.g. if they’re mapped to/from I/O, or permanently retained in non-volatile memory)
- the notions of functions and function blocks
- a number of standard functions and function blocks that are like built-in operators

Some things in the standard that I would have expected to be supported everywhere, e.g. simply declaring a variable as a temporary, just aren’t and sometimes a supposedly standard function block either isn’t supported, has a different name, or has differently named inputs on a particular platform.
For the most part, though, you can trust that if something is in 61131 it’ll be possible on whichever platform you’re using.
The final thing to bear in mind is that the PLC wants to know everything it’ll be doing—both the amount of memory it will be using and the call tree—precisely, before it ever starts up. This has implications on what you can do and which programs will actually compile, covered in the limitations section below.
PLC caveats and limitations
In order to perform it’s duties as expected, the PLC has a bunch of limitations that you want to be aware of throughout.
Scan time
First off, you’ve got to finish each scan (basically each run through your main loop) within a certain well defined time (say 4ms or whatever you setup). Not doing so will land you in some sort of hard fault from which you probably can’t recover from within the program.
I/O
You’ll most certainly be using I/O and the main thing to remember is that you should think of it as if the actual reading of inputs and writing of outputs happen outside of your program loop.
This means that if you fiddle around with some digital output, changing it from HIGH/TRUE to LOW/FALSE 20 times during a single scan, you won’t see this happening on the actual wire—only the last value you set in that whole scan will actually be reflected on the data line. So, if you’re bit-banging some line then the fastest bit-rate you can achieve will be related to your scan interval and nothing else.
Same goes for inputs—a value you read in at any point in a scan won’t suddenly change mid-way through. It’s read prior to your scan, and then again prior to the next scan.
Nesting limit
Then, there’s probably going to be a pretty slim nesting limit.
I’m used to breaking down my programs into small, easy to understand and maintain, units that focus on a single job. It’s a great practice, but at some point with a PLC you’ll hit the nesting wall, which is how deep you can go in your call stack.
For example, with the Omron NX1P2 this limit is 8. So from your main program, you can trigger some function block, which triggers another, which triggers whatever down a total of 8 levels and no more. It’s one of the reasons you can’t do recursion: the PLC can’t figure out how deep it’ll be going during the compilation stage.
Typing
You can use the built-in data types and you can create more complex structures by building them up, bundling built-ins and user-defined types in layers.
Do not, however, expect to use any forms of polymorphism or composition. If you’re going to have two bots, it makes sense to have them both be of some custom type “Robot”.
If, say, only one of these bots has a specific bit of hardware then there are tons of C++ solutions to this—say deriving a RobotWithIRSensor from your basic Robot, or composing a Robot as some basic class with a dynamic list of additional hardware modules which provide a common interface, or whatever—and there are extensions to the PLC standards to support OO-type deals too, but if you want your programs and skillset to be portable then, for now at least, stick with the KISS principle and just use plain old STRUCTUREs.
Using user-defined structures, the bots will either both have fields referring to this hardware (non-existent for the other bot) and perhaps some flag to indicate whether it’s actually available, or the bots need to be of different types.

Memory
Memory usage is an interesting area, with PLCs.
You probably won’t have gigs of RAM, of course, but you’re likely to have more than enough to get the job done.
The difference with regular programming is that you basically have neither heap nor stack.
You don’t have facilities for dynamic memory allocation. Ok, fine, simple enough.
Your functions and function blocks will have values coming in and out, declared explicitly as input, output or in-out—all very explicit and CORBA-like, if anyone remembers those good old days.
Function block aren’t functions
What’s weirder is that every single variable you use is basically declared statically and will be around for ever and ever. That “i” you used in a for-loop during initialization? Yep, it’s memory resident as long as your PLC is running.
So for some given function block you’ve got:
- globals, which are external variables obviously always around
- in/out/in-out parameters
- locally declared variables
These last, which on other platforms would be given space when you enter the function, space which would then be reclaimed for other purposed on return, both keep using up memory all the time and retain their state. Here’s a simple PLC-world, function block that declares it uses
- SOME_INPUT: INT, input
- BOT_INOUT_STRUCT : Robot, in-out
- SUCCESS_OUTPUT: BOOL, output and a
- GLOBAL_CONSTANT_NUMITEMS : INT external
and also an INT (i) local for looping around. Say has a body with something dumb like
SUCCESS_OUTPUT := FALSE; (* reset on every call *)
FOR i:=0 TO GLOBAL_CONSTANT_NUMITEMS BY 1 DO
(* do something *)
END_FOR;
IF whatever() THEN
SUCCESS_OUTPUT := TRUE;
END_IF;
Then it might look something like this if implemented in C++ the way it is behind the scenes in a PLC
static int GLOBAL_CONSTANT_NUMITEMS = 10; /* an external variable */
class SomeFunctionBlock {
private:
int i; /* value only used in our method, but will stick around */
public:
bool success; /* our output value, also sticks around */
void operator(int SOME_INPUT,
Robot & BOT_INOUT_STRUCT,
bool * SUCCESS_OUTPUT) {
success = false; /* reset on every call */
for (i=0; i<GLOBAL_CONSTANT_NUMITEMS; i++) {
/* do whatever */
}
if (whatever()) {
success = true;
}
/* whenever we actually return, this is done for you */
if (SUCCESS_OUTPUT) {
*SUCCESS_OUTPUT = success;
}
/* now user can either pass us a success value to set when
calling, or just access our internal .success whenever */
}
}
/* and now, a way to use the class, an instance of the function
block, wherever you are using it */
static SomeFunctionBlock myFB;
The lessons are that the block itself will be more like a type than a function, with a statically created instance to call it with when you use it.
The in-out are passed like references (so you should use these for fat structures even if you’re not modifying them within the block), any outputs are set in your caller on return but are persistent parts of the FB and any local variable used within is statically allocated and persists as long as the program is running.
After the function block is actually used, that “i” loop counter will still be living somewhere in memory and be set to the value 11. The success boolean output, which I had to give two distinct names to here because it’s C++, would also stick around and in fact be accessible through the function block as a kind of member of the FB instance, say myFB.SUCCESS.
This all can be super useful.
Example: you have a function block that gets called repeatedly and needs to do some initialization the first time around, which it skips later on. In that case, your locally declared “wasInitialized” BOOL can be set to TRUE in the init, which will can then be skipped in the future
IF NOT wasInitialized THEN
(* first time here, so we do the stuff
* and remember to set the flag to skip next time *)
wasInitialized := TRUE;
END_IF;
(* rest of the function block… *)
It can also bite you if you’re not careful or assume a “fresh start” every time you are called. Say your have some success flag output, a safe approach in such a block would be to always:
(* start by re-setting our success flag, so we
* never return success untruthfully *)
SUCCESS := FALSE;
(* check conditions that cause the operation to fail *)
IF NOT readyToDoIt() THEN
(* this test has failed, we can just return *)
RETURN;
END_IF;
(* do other checks and whatever we’re
* supposed to, and finally: *)
SUCCESS := TRUE;
That way, you ensure you never return an old TRUE when the call actually failed.
With all these variables staying resident in memory forever, you need to be mindful of your usage but there’s no need to panic.
For a recent mid-sized project, on a relatively low-end PLC, I wound up with about 100 datatypes, 200 functions/function blocks and almost 700 POU instances and still had 25% of the memory in the PLC left over by the end of the day.
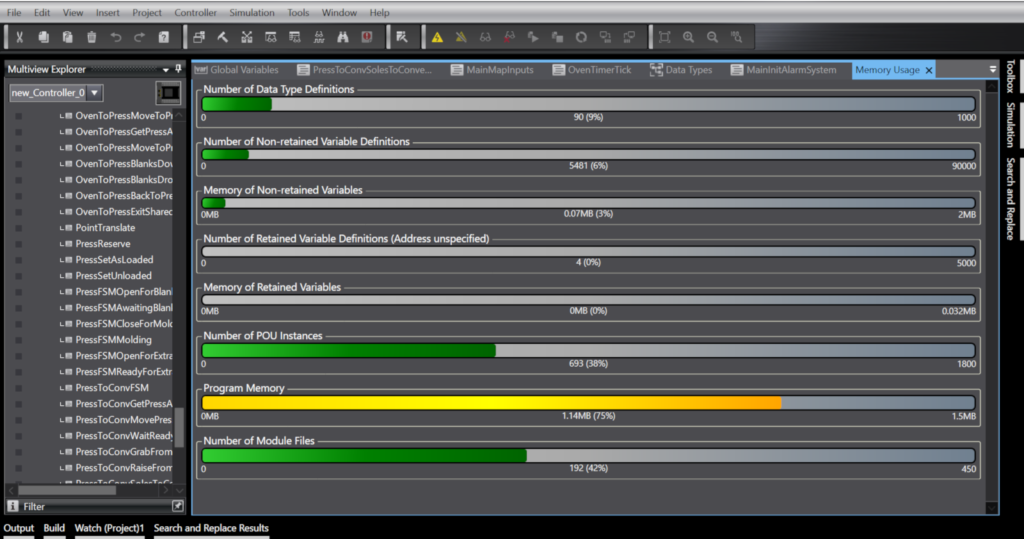
So be aware of the situation, don’t use an 8 byte ULINT for each of your loop counters when a simple UINT will do, and choose functions over function blocks where it makes sense but don’t sacrifice clarity or maintainability for a few bytes of RAM when it isn’t required.
PLC Hardware
This article is more about the software side of the equation but there are three things that should be mentioned concerning the hardware in these industrial systems.
Voltage and current

Not that it matters from a programming perspective but low, logic level, voltage may be higher than you’re used to if you usually deal with IoT or processors… no 3v3 or 1v8 here, more like 24V. Analog sensors that act as current sources will often have a full-scale range of 4mA to 20mA, which differentiates between a 0 reading (4mA) and a missing sensor (0mA).
The panel itself may deal with really high voltages and currents which can be downright scary if you’re more accustomed to dealing with coin cell powered BLE devices.
Logic Levels
Irrespective of the actual voltages involved, the principles of digital I/O are the same as everywhere else. One thing to note though is that, in the case of important safety systems, the logic is often inverted.
The e-stop or other critical components will often provide you with a HIGH signal to indicate that there are no problems, more like an “everything is still OK” signal, and transition LOW when something is amiss. This allows for safer operation as loss of the signal, for any reason, means things aren’t working as planned.
Modularity
In order to be modular, lower cost and use proven reliable parts, these control systems are built up in a modular fashion by adding distinct modules as required by the application. For some things, like adding I/O ports, this involves little more than slotting in the module to the side of the PLC itself.
For others, like heavy duty servo controllers, they are stand-alone and may be controlled through some protocol like EtherCAT.
The point is that for those used to nice integrated solutions, the final system will look more like a giant breadboard than a finished product. This can be clean and clear while still allowing for swapping out major components or making changes down the road.
Or it can be a giant spaghetti mess.

Programming the PLC
To program a PLC, you’ll start off as usual, by defining the data types, flow charts, state machines etc that you need to get the job done. Then its time to start coding.
The Program
You’ll have at least one, and perhaps more, programs in your PLC.
Each program will be run, from start to finish, repeatedly depending on configuration: a single pass through the program is a “scan”. The scans can be triggered by events or a just run at a certain frequency. In the simplest cases, you’ll have one program being run every n milliseconds.
The program uses logic, functions and function blocks to do the job at hand.
Telling the PLC what to do
When it comes time to start implementing, you’ll want to consider the best language to use (either for the whole program or on a block-by-block basis). There are a number of standard languages (both graphical and textual) and the most widely supported are ladder logic (graphical) and structured text.
Ladder Logic
Ladder logic is graphical and looks like an actual circuit filled with switches and relays.
It may be well suited to simple scenarios where an input triggers some operation (say a timer) which then energizes some output, and it’s a great way to visualize conditionals.
A string of switches must all be closed for the signal to flow through them (so series connections are ANDed logic), and parallel connections offer multiple paths which is just an OR clause.
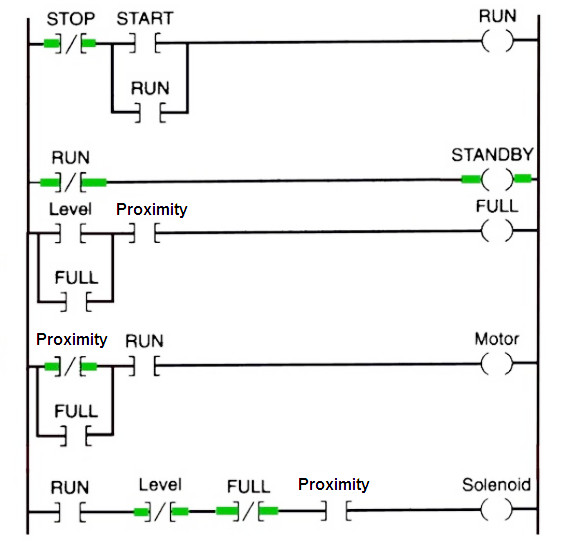
I’m not a huge fan of ladder logic: you have to enjoy using your mouse a whole lot and I’d hate to be doing the math I’ve been playing with with a zillion little blocks but different strokes etc.
Structured Text
Structured text is frikkin’ old school, feels like Pascale or shell scripting and uses statement terminators rather than braces for blocks.
I seem to do a lot more assignment than comparison, so having to type the extra colon every time is a minor peeve
myVarialble := TRUE;
and the language makes me feel like I’m making a mistake everytime I do a comparison because the code would mean something else in pretty much every other programming language
IF someValue = 42 THEN
aLogicErrorInEveryOtherLanguage();
END_IF;
It isn’t case sensitive and has a few inconsistencies I can understand but get to me, like the default/catch all for CASE statements being written differently then every other case, which always forces me to pause for a second
CASE mybot.state OF
EATING:
doEat(bot := mybot);
SLEEPING:
doSleep(bot := mybot);
ELSE
DidYouCatchTheLackOfColonUpThere();
END_CASE;
Still, the language is legible and has all your basic comparisons and loops covered, with built-ins dealing with pretty much everything else.
One final thing about the language is that some things you might expect to be part of the syntax, say a simple bit shift are in fact present but not very natural (instead of “1 << 3”, you’d SHL(1, 3) or something).
On the other hand things like timers (TON/TOF), counters (CTU/CTD) and signal debouncing/one-shots (R_TRIG/F_TRIG) are part of the standard set and really easy to use.
Functions v. Function Blocks
When you’re doing more than simply stringing together built-in functions, it will be important to know how to choose between creating functions and function blocks.
Functions
Functions are just what you think. They take arguments and have a single return value.
The main idea is that if the same inputs go in, the same result/outputs come out. Functions you create are available anywhere in your program, and all you need to do is call them as you would in any other environment:
IF CheckMyThing(param1 := 22, param2 := FALSE) THEN
(* ... *)
END_IF;
or whatever.
For the function to be truly deterministic, it’s responses must only depend on the values of the inputs. This implies that referring to some external global in a function is either not well regarded or simply not possible, depending on the platform.
One irritation I have with Omron’s IDE is that it gripes and gives warning about functions that use external “variables” even when those externals are defined as constants but my complaints about sysmac studio are a topic for another post.
Function Blocks
Function blocks are horribly named. They are basically definitions for a class-type thing which supports a single method (see the memory discussion above) and has members that reflect argument/local variables.
If you define function block X, say with the same parameters as used in the discussion on memory, then you can access X’s functionality in many parts of your program, similar to a regular old function. The things to note are that:
- You can’t just call a function block as if it were a function, you’ll need instead to declare an instance of that X function block where you’ll be using it, say
doX : X - When you want to trigger the block, you make the call on the instance itself as you would a function
doX(SOM_INPUT := 42,
BOT_INOUT_STRUCT := mybot,
SUCCESS_OUTPUT => was_good);
This doX instance of the X FB will be statically held wherever you declared it, and its internal state will be maintained. Of course, if you declare another instance of X somewhere else, it will have it’s own internal, and independent, state.
Final thoughts, tips, tricks and resources
With all the above, you should be well on your way to getting started. Here are some additional tips and thoughts.
Platform
You can find loads of tutorials online but the downside with many of them is that they inevitably settle on some particular proprietary platform (e.g. Rockwell RSLogix) that probably only runs under windows, may or may not be appropriate for your situation and will likely be some kind of trial version or crippleware.
A good way to get started is with OpenPLC, that has both an editor and a runtime that can get you playing with PLCs on many platforms including a plain old Raspberry Pi.
The editor is far from perfect but it works, has an ok simulator and the fact that it’s in Python means you can always do like me and extend/enhance it to meet your requirements and contribute the mods back to the project.
Triggering Function Blocks
Many standard function blocks exist and are very useful. Even if you’re spending all day typing in structured text, it’s important to remember the ladder logic/electronic roots of this stuff because sometimes it may not be obvious.
Initially, I started using some FBs and they just weren’t behaving as I expected.
The Execute or Enable input was TRUE but the thing wasn’t doing its job. Took me a while to figure out that the motion command, timer or whatever was implemented not to run when that input was HIGH but to actually latch on to the transition from LOW to HIGH.
In essence, the Enable had to be false and then go true for it to actually operate.
Avoiding Carpal Tunnel
These PLC folks love their mice.
I’m not the type who only swears by emacs/vi and use a variety of IDEs to code, and I can understand making things nice and graphical and such but it gets ridiculous even if you’re doing structured text rather than ladder.
Here’s a legal ST declaration for 2 input variables:
VAR_INPUT
bot: Robot;
destination : Point;
END_VAR
I can type these in the space of two breaths but most IDEs will force you to enter them in some distinct window pane (pain) and go through a whole lot of mouse work to do it.
In one IDE the process is
- Click Variables to show the pane
- Click “in/out” tab
- Right-click, move mouse to “create new” and click that
- Click name field once or twice, type name
- Click direction select box, move to “in” and select that
- Click type box, start entering the type name, select type and enter
That’s 10 or more mouse operations on top of the typing you have to do anyway. You do save on typing the ‘:’ and ‘;’ characters though. Not worth it.
There are some optimizations and down-right work-arounds I’ll get to in another post but this is all pretty hard to avoid in general when dealing with PLCs.
Short version is: and make sure you’ve got an ergonomic setup, without a num-pad to jump over all the time, and grease up your mouse.
Additional Resources
The PLC Academy has a nice page with info about the standard function blocks
The Open PLC project is all around cool and useful.
Flip that around and you can access the PLCOpen association, which has a number of resources available.
The PLC Programming From Scratch series, by Paul Lynn, is a bit hard to get through if only because it moves soooo slowly and it’s very focused on the RSLogix software, but it definitely covers all the bases and is a good way to start.