My client needed to receive a relatively large amount of data on a mobile device, from an embedded system, and process it in near-realtime. The simplest method for communication with a whole host of mobile devices is to go over bluetooth low energy, but this protocol’s main concern is more about power conservation than throughput. Getting enough bytes across, fast enough, required some finagling. Here I present the technique used, the results and some tips on squeezing more data through the BLE tube.
Objectives
In order to have enough samples for meaningful analysis the goal was to get ADC data from two Raman probes at 300Hz for a total of 600 samples per second, or 1200 bytes every second of raw data (2 probes * 300 samples * 2 bytes/sample).
In addition, because we wanted an accurate representation of the state of our probes and can’t trust the timing–or even the ordering, in fact–of the data packets themselves, there was some overhead for meta information, namely timestamping, which brought us up to a total of 1500 bytes/sec, using the devised system.
We also wanted to minimize the amount of external hardware, so a system with an on-board Analog-to-Digital converter that is fast enough to keep from impacting our sample rate was needed. This is, thankfully, almost everything these days so it was mainly a question of getting an embedded platform that we could program easily and would have BLE support built-in.
Finally, on the mobile app side the aim was to
- do some number crunching on the stream of samples;
- log all the derived data to permanent storage; and
- dynamically update the UI with a bar graph, running averages and such.
Obstacles
BLE
A throughput of 2 kilobytes/sec is laughable when you’ve got Gigabit ethernet or even WiFi at your disposal. Bluetooth 4 is another story, though. The first obstacle, as mentioned, is the BLE comm layer itself. More specifically, the protocol uses packets that have, at most, 20 bytes of payload which isn’t a huge MTU to begin with.
But simply breaking up your data into 20-byte blocks doesn’t necessarily solve the issue, because the actual throughput you can get with bluetooth low energy depends on things like the connection interval and the number of packets that can actually be sent/received within that interval. So your throughput will really be:
20 bytes * number of packets sent per connection interval * number of connection intervals/sec
Exact specifics are unfortunately OS- and device-dependent.
App
On the mobile side: processing, memory and slow filesystems become a concern.
I primarily do my mobile app dev on Android, and try to get it all working on an HP 7 G2 tablet . As of today (May, 2016), this thing considers itself “up to date” running Android 4.4.2–thanks a bunch for the long term lovin’, Hewlett Packard.
It isn’t a fast machine, the bluetooth layer sucks and writing to the onboard flash is unbearably slow. As a user, I’d be sourly disappointed. However for development this tablet is great because if I can get something running reliably on this total P.O.S. then it’ll perform smashingly pretty much anywhere.
So, as I’m running most tests on the HP, and as the app has stuff to do beyond simply receiving the data, in addition to the comm layer’s built-in limitations there’s another bottleneck on the app side.
Other things to deal with are that a certain percentage of the packets are actually lost to the ether but, more importantly, they are sometimes passed to me by the lower layers after a delay, in batches and occasionally out of sequence.
Solutions
After a bit of research, coding and testing here are the results as delivered to the client.
Embedded platform and measurements
The BLE Nano was a good choice for the hardware side, as it has 5 analog inputs, runs at 16MHz and handles all the gritty details of bluetooth low energy for us.
The ARM Cortex M0, which is beneath the hood of the Nordic nRF51822 which itself is beneath the hood of the BLE Nano, can do ADC conversions in about 70 microseconds. Even accounting for some overhead from the upper layers, this gives us the opportunity to measure two inputs at a rate of over 7kHz–way more than fast enough here.
To take advantage of this, I decided to smooth things out a bit and take 5 measurements from each channel, every 2/3 of a millisecond. Averaging these 5 measurements out to produce a value every 3.33 ms achieves our target sample rate of 300Hz while blurring out line noise.
Throughput
The first thing to do is to get the packets across with minimal overhead, which implies sending packets that don’t require too much handshaking or acknowledgements. Notification packets are the UDP of BLE-world and can be queued for sends. They will be broadcast to the subscriber in sequence without regards to whether the receiver actually picked up the data or not. So using notifications is fast at the cost of being less reliable.
Even using notifications the amount of data we can get across is limited by the payload size, the connection interval and the number of packets that can be exchanged in a single connection event. The limiting factors are:
- it seems some iOS versions will limit you to 4 packets per event, which may also be true for most Android devices;
- though the lowest connection interval, per the spec, is 7.5ms some Android devices won’t handle connection intervals of less than 37.5ms.
If you try to account for the worst case scenario, combining the factors above, you find that if you can probably get about 100 packets through in a second (so ~2000 bytes). This is enough for our needs, if we’re careful about how we package the data.
To avoid losing too many packets the SNR can be increased at the cost of battery life, so you can start by increasing the transmission power.
The connection interval is decided by the mobile app side, but the BLE server can still let its preferences be known. Specifically for the BLE Nano (using the BLE_API), you can set your preferred connection parameters using the Gap this way:
// get a struct with preferences to pass to setPreferredConnectionParams()
Gap::ConnectionParams_t connParams;
// welcome to the Gap (get a reference)
Gap & gap = MyBLEDevice->gap();
// set the minimum to ... the minimum allowable
connParams.minConnectionInterval = BLE_GAP_CP_MIN_CONN_INTVL_MIN;
// set the maximum we'd prefer such that we can get 3 packets accross in time
// 1000 ms * 4 samples/packet * 3 packets per interval / (1.25 ms units * Freq)
// at 300 Hz, this gives 32 units of 1.25ms (so 40ms, or 25 connection events/s)
connParams.maxConnectionInterval =
( (100000ull * 4 * 3)/ (125 * SAMPLING_FREQUENCY_HZ) );
// other stuff... whatevs
connParams.slaveLatency = BLE_GAP_CP_SLAVE_LATENCY_MAX;
connParams.connectionSupervisionTimeout = BLE_GAP_CP_CONN_SUP_TIMEOUT_MAX / 2;
// now, actually set your preferences
gap.setPreferredConnectionParams(&connParams);
and cross your fingers that the mobile device will respect your preferences to the best of its abilities.
Chunking
Trying to send values in real-time in this case would mean, at best, sending 300 packets per second which busts our throughput limit.
In order for this to work within our 100 packet/s constraint, data needs to be grouped together. Because of this, and because we can’t rely on the OS to hand us the data at the very moment it arrives–or even, as mentioned, in the exact order it arrived in–we also need a way to timestamp and/or sort the data.
The solution to both issues is to group the samples together and add some meta-information concerning the specifics of each sample batch. Here’s the packet format finally established:

A 20 byte packet contains 4 samples from each of both channels, using up a total of 16 bytes. The packet also includes two other fields:
- a single byte Type field; and
- a 24-bit sequence number
In this case the type field was used to specify under which circumstances the samples were being taken (normal sampling, various types of calibration, etc) but I feel it’s a good idea to have something equivalent in there in most circumstances, as it allows for future revisions and extensions without impacting the whole system.
The sequence number is generated by the embedded system and is a much steadier source for timing than anything we get from the mobile side of the equation. It allows us to know
- the timing of the incoming samples (when they were taken);
- the true ordering of the packets as they are process by the mobile;
- the total run time of the sampling run at any moment; and
- it also gives us the opportunity to know if any packets were never delivered.
In short, when sampling begins the firmware resets this sequence to 0 and increments it for each queued notification. Since samples are prepared every 3.33 ms, and packets will be queued for send whenever 4 samples (from each channel) are ready, we know that packet n was queued at n * 13.33ms from the start of the run.
This counter uses 3 bytes, so will eventually overflow. However, at our relatively modest packet send rate, we get to continue a sampling run for over 62 hours before this happens–not really an issue in my specific use case.
Mobile App
On the application side the fact is that if all you’re interested in doing is receiving the data, things go pretty smoothly.
However, because of the need to do some processing on the data and the writes to the (slow) flash, more work was required to account for the data being handed to the program in batches and out of sequence. The gist of it was to use the packet sequence ID and the knowledge that all the samples in a given packet were taken at a know interval: so, sample 1’s timestamp is
sequence number * packet send period
and every subsequent sample (for a channel) in the batch is just 1/sampling frequency later than the last.
Also, the application needs to store 36000 samples every minute. This isn’t an overwhelming amount of data but because I like to use an ORM atop an SQLite database when doing mobile, and because this specific ORM was designed to automatically track changes to the objects (namely by keeping them alive in memory), after a certain time RAM became an issue.
I could have dropped the ORM altogether for these samples, but that would have introduced two systems in the program, one for ORM-based data and another for “raw” bits… not cool. Instead, I wound up hacking the ORM to indicate that certain types of objects should be exempt of tracking (meaning they were “write-once” in essence). I’ll be packaging these changes up and releasing them back when I have the time.
Finally, writing out the db data to a CSV file was a annoying, too, again because of flash access speed and RAM. The approach used may be worthy of another article… suffice it to say that it wasn’t all that fun, but it’s eminently doable.
Results
The final combination of the firmware making measurements and packaging up the samples with the app processing the data and logging the results works quite well. Here is a graph of 10 seconds worth of data on one analog input, as processed and exported to a CSV and plotted using gnuplot:
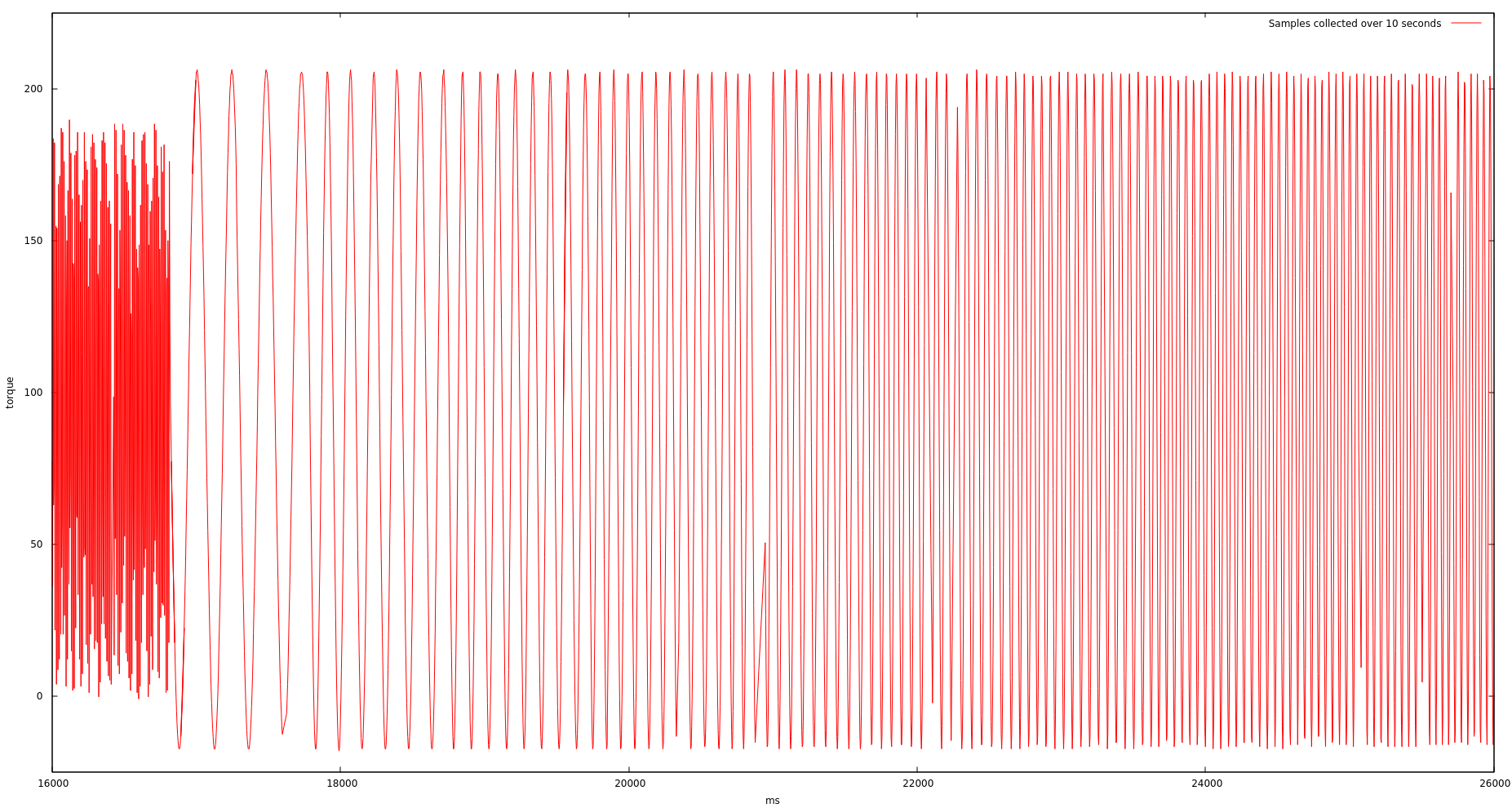
Samples collected over 10 seconds
You can spot a few holes in the data, namely near the 21 second point in the center, which are due to packets actually being dropped. Still, the packet loss is below 3% and we get enough information to perform our analysis.
Here’s a zoomed out view of the same dataset, over about one minute, which was produced from a sinewave incremented slightly every second up to about 100Hz.
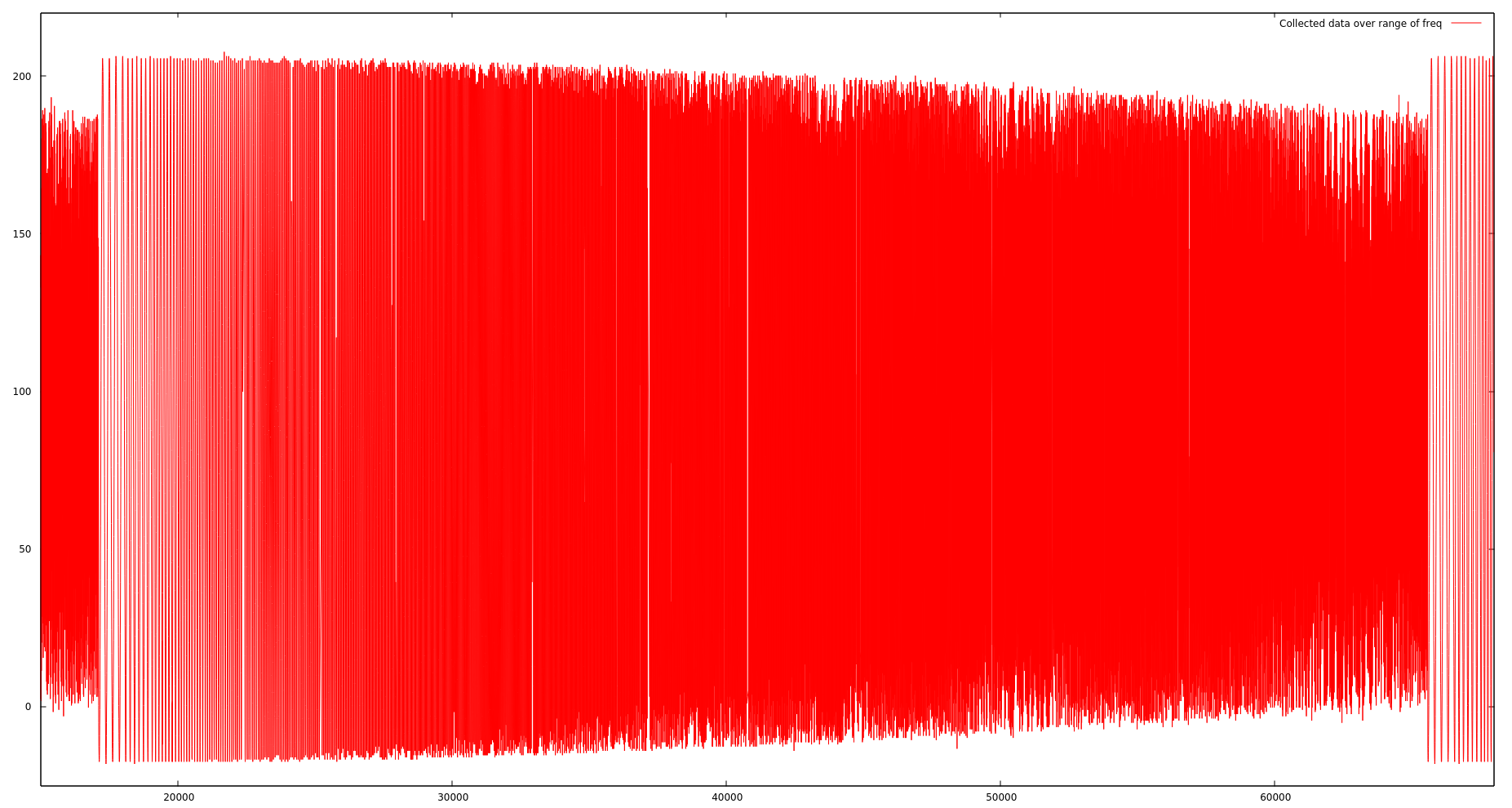
Data over range of frequencies
Possible Enhancements
This whole project centered around getting 2 samples at 300Hz, so an effective data transmission rate of 600 samples/sec… what if you need more juice?
The first and most obvious optimization comes from noting that our samples aren’t actually 2 bytes wide. In this case, the ADC produces 10bit values (from 0 to 1023), so by using our payload more judiciously, we could actually pack 12 samples in each packet (or 6 per channel, rather than the 4). Changing nothing else in our setup, we’d suddenly be getting individual samples at 900Hz, rather than 600Hz, while still only receiving 75 packets per second.
The cost is one of processing on both ends–every packet would need a more involved operation to insert and then extract the 12 10-bit sample values.
Also, assuming the worst case scenario for BLE throughput might be overly conservative. If you can require a specific device, or if testing reveals that you can generally get a lower connection interval with the devices you use, then you can speed things up. Even keeping to our limit of 4 packets per BLE event, if you can get a connection interval down to the spec’ed minimum of 7.5 ms then you’ve just (more than) quintupled the throughput!
Combined with the more efficient packing described above, you would suddenly be transmitting 10-bit samples at an effective rate of 4500Hz… not too shabby, as long as your recipient can actually handle it.
All in all, if 1200 bytes/second is enough for your needs then you can use an adapted version of the technique above. If you want to squeeze out more, try out the two additional approaches mentioned, experiment and see how far you can push it.
Now, have fun playing with all those datapoints.